This post was a hand-wavy sketch of an idea. It now has a concrete example.
Unsupervised Learning and Graphs
The problem discussed in this post is this: you have a signal recorded at different nodes of a graph. These could be prices of the same commodity at different locations, or blood sugar measurements on a given day for different individuals. You choose the graph definition and the signal to measure at each node. Can you infer which nodes to connect to create the edges of the graph based on the signal values?
The graph is considered undirected. The intuition is to fit a model to the nodes of the graph that smooths the signal, i.e., when you connect the nodes of the graph, you get a smooth signal value. The implication is that nodes with similar values will be connected. This is a filtering approach to learning a graph.
There are two unknowns here: the connectivity of the graph and the smoothed signal value. The graph is defined by its Laplacian matrix, \(L\). This is what you want to learn. The smoothing idea is called Total Variation Smoothing and is quite popular. The algorithm consists of two steps:
- Initially, assume the smoothed signal is the same as the observed signal; in subsequent iterations, use the smoothed signal from the smoothing step (value from step 2 in the previous iteration) and learn the Laplacian that makes the signal smooth.
- Using the Laplacian from the previous step and the raw observation values, learn a smooth signal.
This is the algorithm called GL-SigRep in Dong et al. (2016).
To validate this approach, I used the charge-offs in the SBA 7a loans dataset, prepared here and available here. To prepare the data, I did the following:
Selected all loans that were charge-offs.
Grouped the results by state and computed the number of charge-offs in each state.
In the raw dataset, computed the number of loans for each state.
Computed a charge-off rate for each state. This is a small number. I multiplied this by 100 to derive an attribute called CP100; this is the charge-off rate per 100 loans in that state.
Thus, graph nodes are the geographical states (TX, VA, etc.) and we observe the CP100 attribute for each state. Can we learn a graph using the total_variation smoothing approach? I tried this and I think the results are good. States with similar charge-off values are grouped together. States with extreme values (high or low) are outliers and not connected to other states. This shows which states are candidates for IID analysis and which are not. Please note that this result is based on the regularization values I have used with this solution.
The results are shown in the figure below.
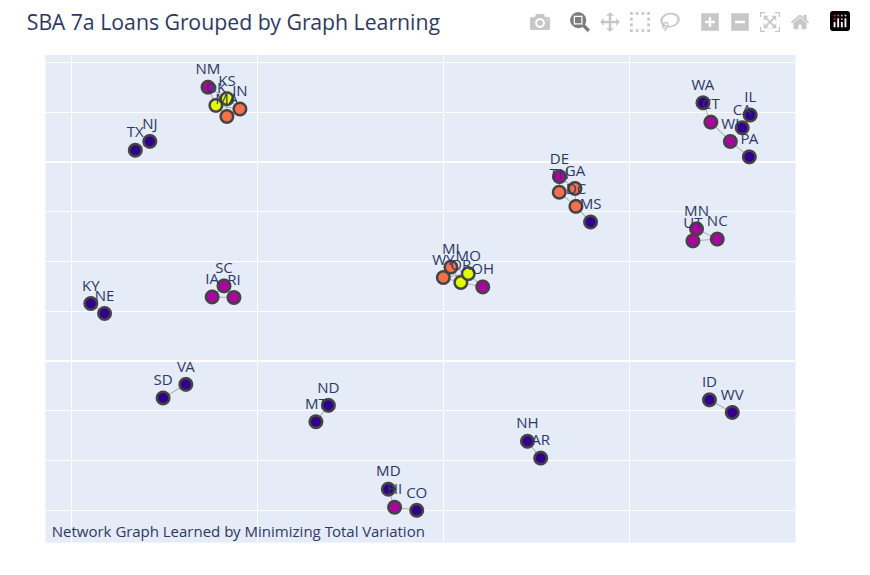
The notebook is available here.
References
Citation
@online{sambasivan2026,
author = {Sambasivan, Rajiv},
title = {Unsupervised {Learning} and {Graphs}},
date = {2026-03-28},
url = {https://rajivsam.github.io/r2ds-blog/posts/graph_learning},
langid = {en}
}