The Black-Box Model
In my opinion, relying on models without prior data analysis is problematic. This is particularly true for business applications that work with regular tabular data. While it’s common practice to develop separate models for prediction and explanation, preliminary data analysis is crucial for justifying: 1. Specific modeling approaches 2. The necessity of certain features
This isn’t just about generating summary statistics or assessing data quality; it’s about understanding the sources of variation relevant to our predictions or estimates.
As a coffee connoisseur, you may have noticed the rising costs of your favorite brew. Imagine you own a small restaurant chain and need to plan your coffee purchases to manage production costs effectively. To forecast coffee prices for the next six months, you hire a data science team to build a predictive model. However, it’s essential to first understand the primary sources of price variation and any recent changes in price patterns before developing an accurate model.
Over the past decade, the quality of libraries for statistical modeling and optimization has significantly improved. Coupled with code generation features like those provided by GitHub Copilot, the effort and cost of conducting data analysis have decreased substantially—provided you have the data analysis skills. Unfortunately, it is quite common to run into conversations today where people believe that throwing the data at an “automatic modeling” tool will give you the answer and there is really no need to understand how the result was obtained.
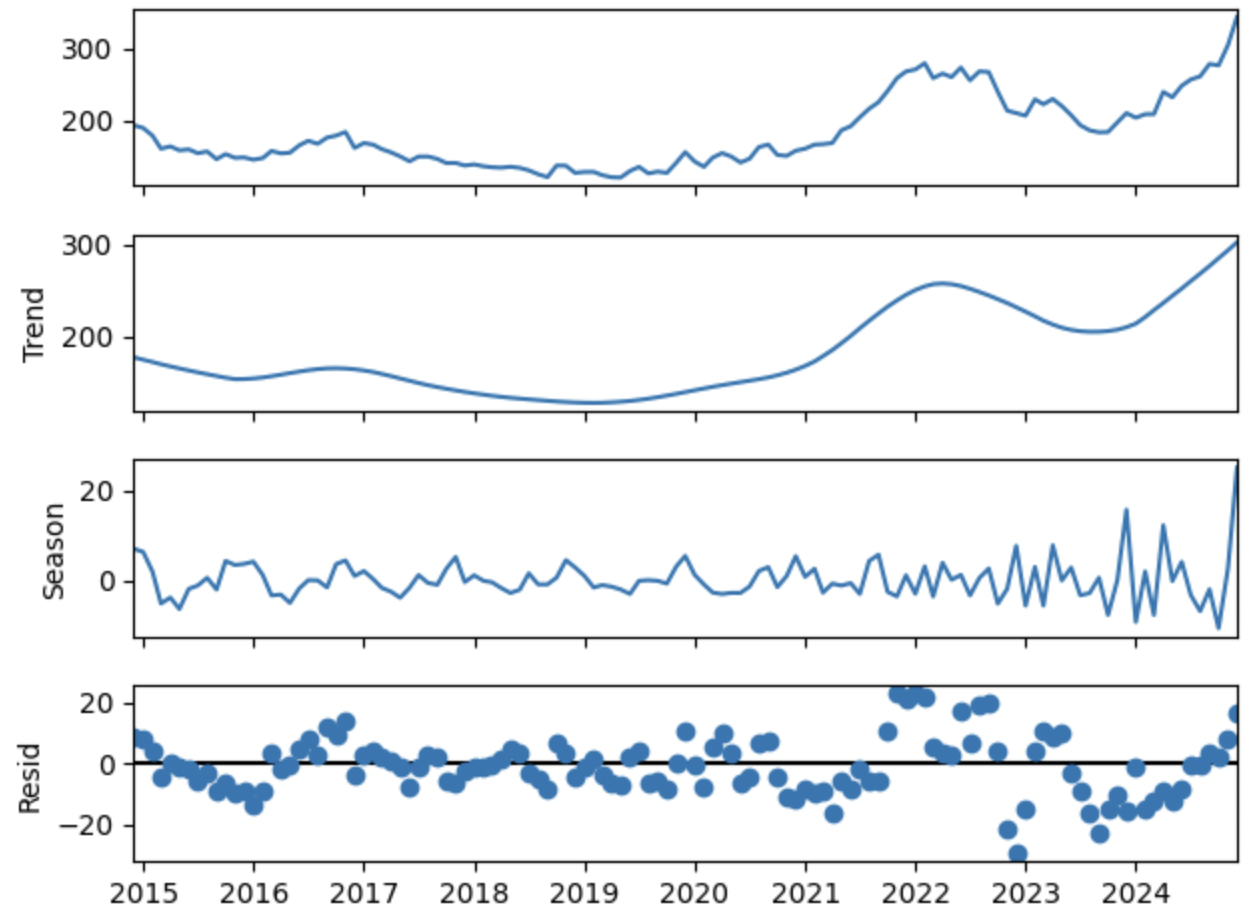
For example, here is how easy tools make this for the coffee example. Here is the raw series 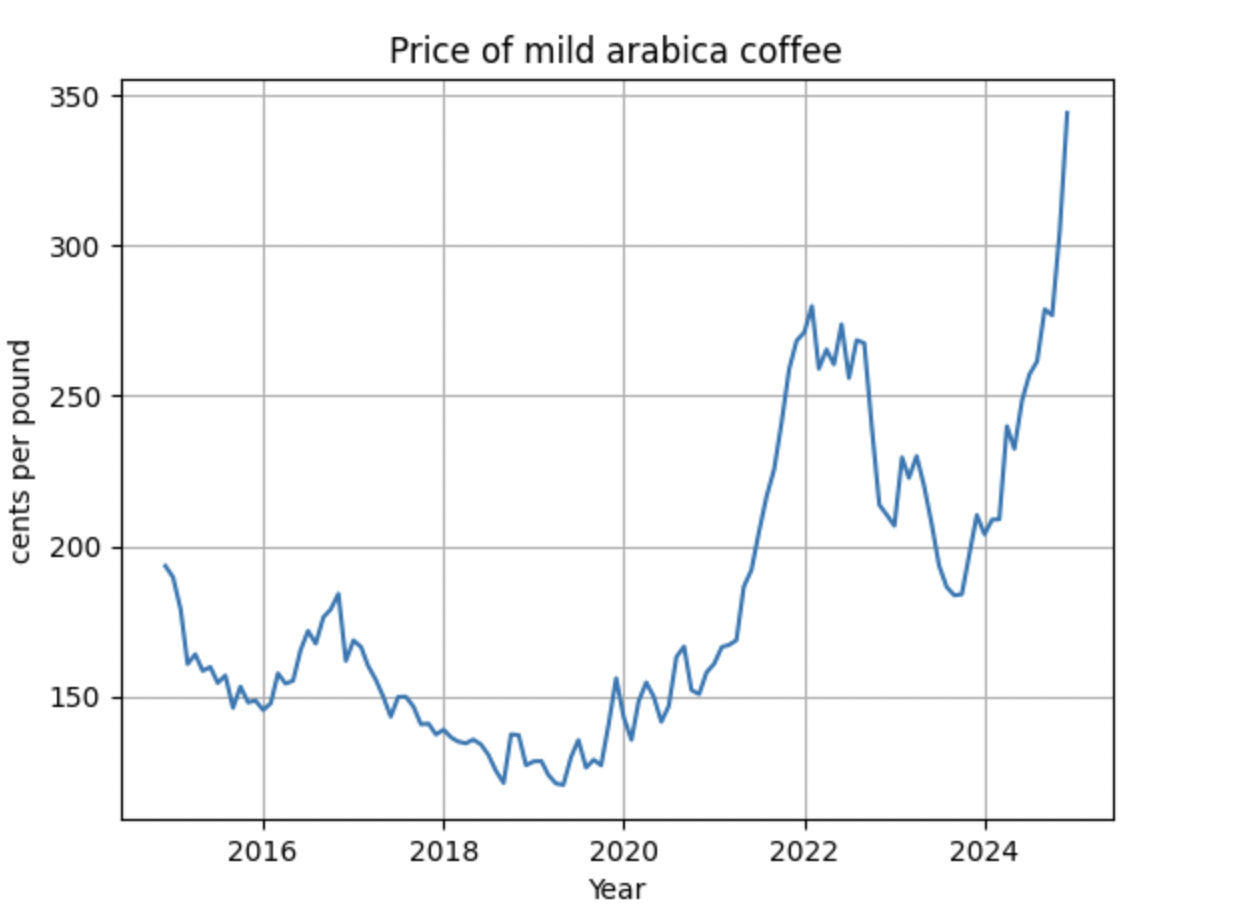 Here is the decomposition of this series with LOWESS. The details of the notebook with the observations are here.
Here is the decomposition of this series with LOWESS. The details of the notebook with the observations are here.